痛点
当流式系统中有多个处理节点,并且多个处理节点需要保持自己的状态信息(比如处理节点每接受到一个消息,就需要根据消息更新自己的状态,如消息记数等),那处理节点应该如何保证 failure recovery 的时候,能自动恢复节点的状态,从而不会造成数据不一致问题?
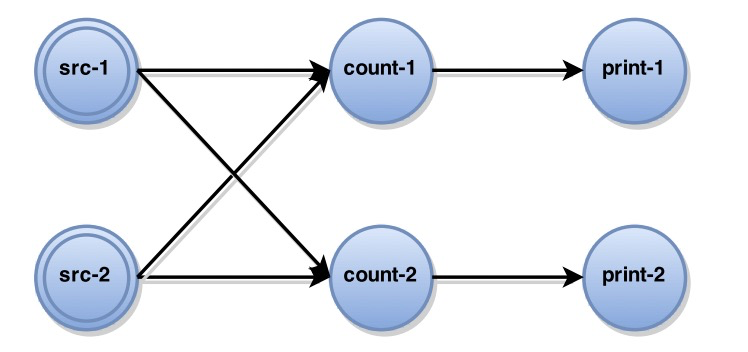 比如上图,当所有的src不再发出消息,那么最终count-1和count-2的计数必须是一样的,且print是只增的。当count-1节点挂掉后重启,如何保证它和count-2一致并保证print-1和print-2最终会打出一样的数字呢?且保证print只增呢?
一种方法是所有节点记住自己所有发出的信息,失败重发,下游记住所有收到的消息和所有每个消息所导致的最新状态,failover之后要求所有上游从失败前的消息开始重发,且只能重发给失败的节点(也就是src-1和src-2要记住不能给count-2重发),且count-1要记住所有这些重发的消息不能导致print打出老的数字(否则违反只增性),而重发结束就要立刻开始给print发出应有的消息。当系统内节点非常多和复杂的时候,记录整个图的消息流动会非常复杂和导致high cost。
比如上图,当所有的src不再发出消息,那么最终count-1和count-2的计数必须是一样的,且print是只增的。当count-1节点挂掉后重启,如何保证它和count-2一致并保证print-1和print-2最终会打出一样的数字呢?且保证print只增呢?
一种方法是所有节点记住自己所有发出的信息,失败重发,下游记住所有收到的消息和所有每个消息所导致的最新状态,failover之后要求所有上游从失败前的消息开始重发,且只能重发给失败的节点(也就是src-1和src-2要记住不能给count-2重发),且count-1要记住所有这些重发的消息不能导致print打出老的数字(否则违反只增性),而重发结束就要立刻开始给print发出应有的消息。当系统内节点非常多和复杂的时候,记录整个图的消息流动会非常复杂和导致high cost。
Chandy-Lamport 分布式快照算法
-
背景
- Global Snapshot Global Snapshot 也就是Global State(全局状态),在系统做 Failure Recovery 的时候非常有用,是分布式计算系统中的一种容错处理理论基础。
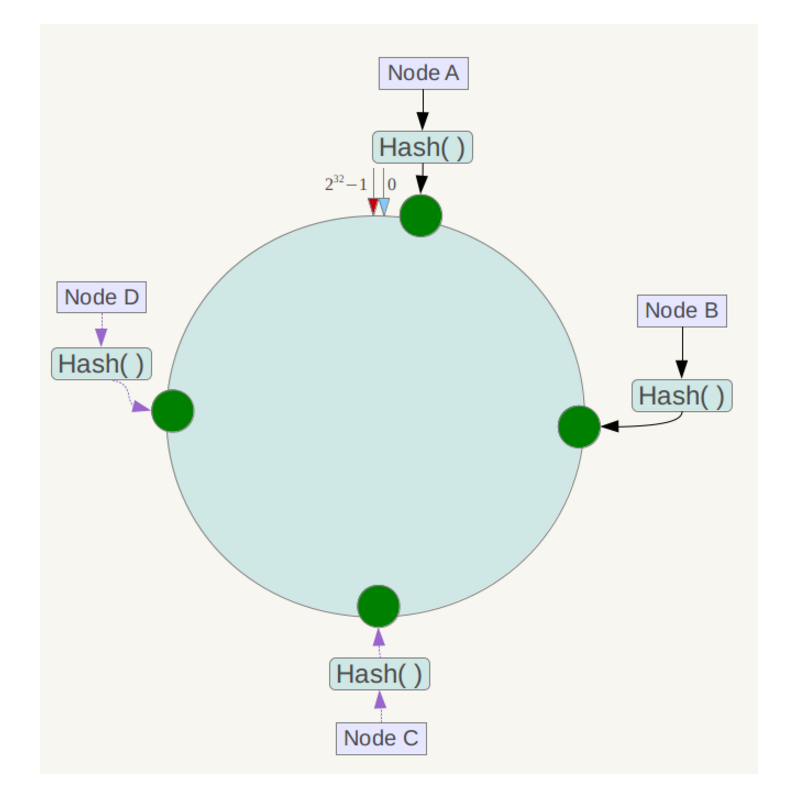
- 有向图 有向图是由一组顶点和一组有方向的边组成。 可以把分布式系统简化成是由限个进程和进程之间的 channel 组成的有向图:节点是进程,边是 channel(包含 input channel, output channel)。在分布式系统中,这些进程是运行在不同的物理机器上的。
- 分布式快照 分布式系统的全局状态由进程的状态和 channel 中的 message 组成,分布式快照算法记录的就是这些进程的状态( local state 和它的 input channel 中有序的 message)。每个进程的状态可以认为是一个局部快照,全局快照是通过将所有的进程的局部快照合并起来得到。
-
算法原理
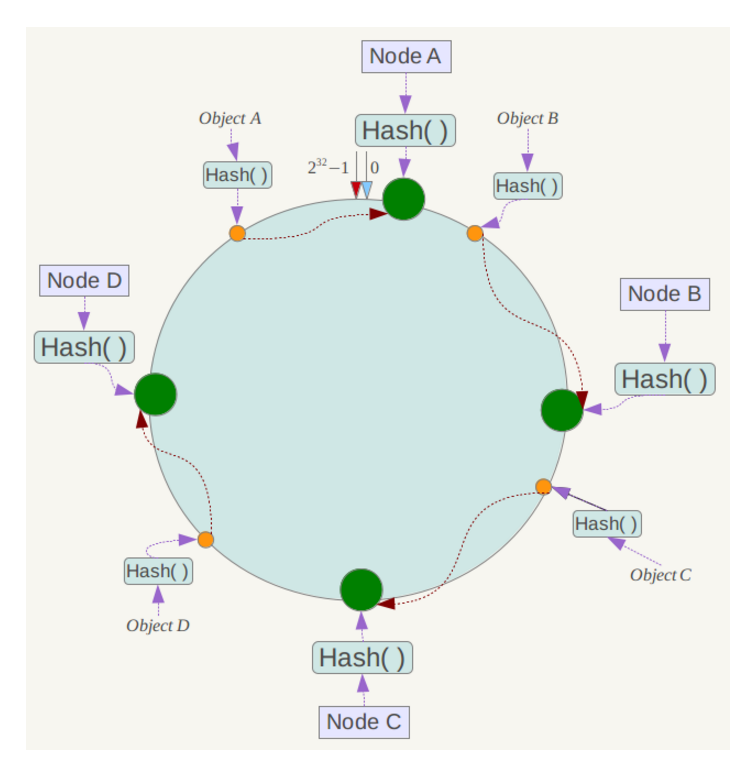
Chandy-Lamport 完成一次分布式快照需要三个步骤
- Initiating a snapshot: 也就是开始创建 snapshot,可以由系统中的任意一个进程发起
- 进程 Pi 发起,Pi记录自己的进程状态,同时生产一个标识信息 marker( 和进程通信的 message 不同)
- 将 marker 信息通过 ouput channel 发送给系统里面的其他进程
- Pi开始记录所有 input channel 接收到的 message
- Propagating a snapshot: 系统中其他进程开始逐个创建 snapshot 的过程
- 进程 Pj 从 某个input channel 接收到 marker 信息后,如果 Pj 还没有记录自己的进程状态,则Pj 记录自己的进程状态,同时将该channel 状态记录为空,然后向 output channel 发送 marker 信息
- 如果 Pj 已经记录好自己的进程状态,则Pj需要记录自己的其他 channel 在收到 marker 之前这些channel 中收到所有 message
- 这里的 marker 可以理解为一个分隔符,进程 local snapshot (记录进程状态)前和后的 message。比如 Pj 做完 local snapshot 之后 一个Channel 中发送过来的 message 为 [a,b,c,marker,x,y,z] 那么 a, b, c 就是进程 Pj 做 local snapshot 前的数据,Pj 对于这部分数据需要记录下来。而 marker 后面 message x,y,x 正常处理掉就可以了。
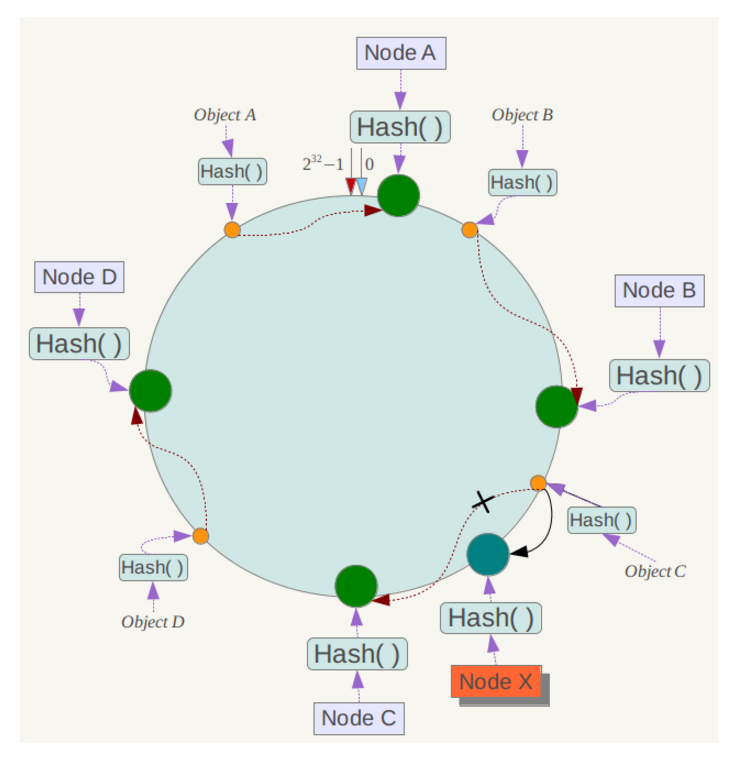
- Terminating a snapshot: 算法结束条件
- 所有的进程都收到 marker 信息并且记录下自己的状态和 channel 的状态(包含的 message)
- Initiating a snapshot: 也就是开始创建 snapshot,可以由系统中的任意一个进程发起
-
约束
- Channel 是一个 FIFO 队列
- Message 有序且无重复
-
总结
- 任何节点的snapshot由本地状态snapshot和节点的input channel snapshot组成
- 任何src可以在任意时间决定take本地状态snapshot,take完本地snapshot,广播一个marker给所有下游
- 任意没有take本地snapshot的节点(注意这个算法里src也是可以接受别人的msg的),假设从第x个channel收到第一个marker的时候,take本地状态snapshot(且take接受到第一个marker的input channel-x的channel snapshot记为空),然后给所有output channel广播这个marker
- 从收到第一个marker并take完本地snapshot之后,记录所有input channel的msg到log里,直到从所有的input channel都收到这个marker. 作为这些input channel的channel snapshot。
-
扩展
- http://lamport.azurewebsites.net/pubs/chandy.pdf
- http://lamport.azurewebsites.net/pubs/time-clocks.pdf
Flink异步快照
Flink解决Exactly Once Message处理的核心思想在Lightweight Asynchronous Snapshots这篇论文里。核心思想是在 input source 端插入 barrier 来替代 Chandy-Lamport 算法中的 Marker,通过控制 barrier 的同步来实现 snapshot 的备份和 exactly-once 语义。它的优点是不需要所有计算节点记住所有发出的信息。只需要数据源可以replay就行了,超级轻量级。
-
Flink无环单向图通信
-
原理
- 需要所有的通信channel是先进先出(FIFO)有序
- 数据源SRC往Output Channel发Message的同时,会有一个中心Coordinator不断广播持续增长的stage barrier到所有的src数据流里。一般是固定时间间隔,比如每5s发送一次barrier。
- 当数据源SRC收到第n个barrier的时候:
- SRC需要保存状态。这样可以保证当需要从任意n位置Replay消息时,可以Replay在自己收到barrier-n之后和第n个barrier之前的所有消息
- 将barrier广播给下游
- 当中间处理节点或最终叶子节点在某个input流收到barrier-n的时候(如果有m个input流)
- block这个input流保证不再收取和处理
- 当所有的m个input都收到的barrier-n的时候, – 保存本地状态(take local-snapshot-n), 保证可以从这个状态恢复。 – 向自己的下游广播barrier-n (如果是叶子节点没有下游,那么不需要广播)
- 当所有的节点(源,中间节点,叶子节点)都处理完barrier-n且完成取快照(take snapshot)的任务之后,就组成了barrier-n的全局快照。
- Failover
- 当集群任意节点挂掉,可以从最近的快照来重启整个系统;即,健康的节点rollback自己的状态到 接收到barrier-n时候 的状态快照。fail掉的节点的通过jobManager用自己的local-snapshot-n重置本地状态之后,才开始接收上游的消息。
- 可以理解为当failover的时候,全部节点的状态都回退到了barrier-n之前的数据源message所导致的全网状态,就好像数据源在barrier-n之后根本没有发过消息一样。不断发出的barrier就好像逻辑时钟一样,然而“时间”流动到不同地方的速度不同,只有当一个时间“点”全部流动到了全网,且全网把这个时间“点”的状态全部取了快照(注意当网络很大,最后一个节点取完快照,初始节点可能已经前进到n+5,n+10了,但是由于最后一个节点才刚取完快照,CompleteGlobalSnapshot-n只到n,n是全局consistent的记录点)
- 如果正常的节点的运算可以自动忽略老的已经处理过的消息(或者说replay导致的消息),那么我们只需要重启所有从源到fail掉的节点的这条线即可。
-
原理
-
Flink有环单向图通信
-
原理
- 当一个节点是环的Message流动的起点时(或者说这个节点正好同时是环的起点和终点),它必定有一个Input Channel是来自自己的下游节点。
- 这个节点不能像其他节点一样,等待所有的Input Channel的barrier到来,才take SnapShot且广播barrier,因为它有一个或多个Input Channel的消息是被自己往“下游”发的消息所引发的。如果它自己不向下游广播barrier,那么这些回环Input Channel永远也不会有barrier发来,那么算法会永久等待。
- 所以这个这个节点只需要等待所有非回环input channel的barrier到了,它就知道所有可能的barrier都到齐了,那么它就可以take本地SnapShot且往“下游”广播barrier了(从而造成barrier会通过回路再次抵达这个节点)
- 此节点take完本地SnapShot之后,需要记录所有回环Input Channel的Message到log里,直到从此回环input channel收到自己发出的barrier,当所有回环input channel都收到barrier-n. 此时在Step3 take的本地snapshot,加上所有回环input channel的msg log一起,成为此节点在barrier-n的本地snapshot。(对于环来说,可能遇到上一个event发给本节点的需要记录的”未来状态”还未到来,但是已经有”new event”(比如从src来的新消息)来改本地状态了,所以不能等待回环的消息,而必须先把本地状态take snapshot了才行,作为”上一个event导致的msg“,只能作为”未来event“记录在stream log里了,当然flink的算法也可以设计为,即使非回环input channel的barrier都到齐了,也不unblock input channel ,而是等待所有的回环input channel的barrier也都到齐了,才take本地snapshot,且一起unblock所有的input channel;这样就不需要维护stream log了。但性能很低)
- Failover,failover的时候,除了从本地snapshot恢复状态之外,还需要replay所有input channel的msg。
-
原理
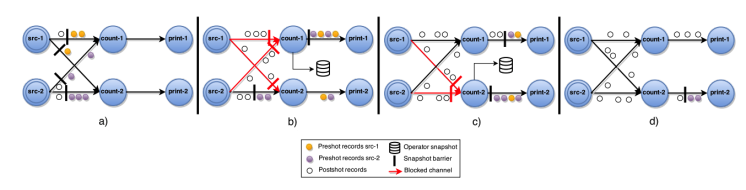 上图描述的是一个面描述 增量计算 word count的Job,上图核心说明了如下几点:
上图描述的是一个面描述 增量计算 word count的Job,上图核心说明了如下几点: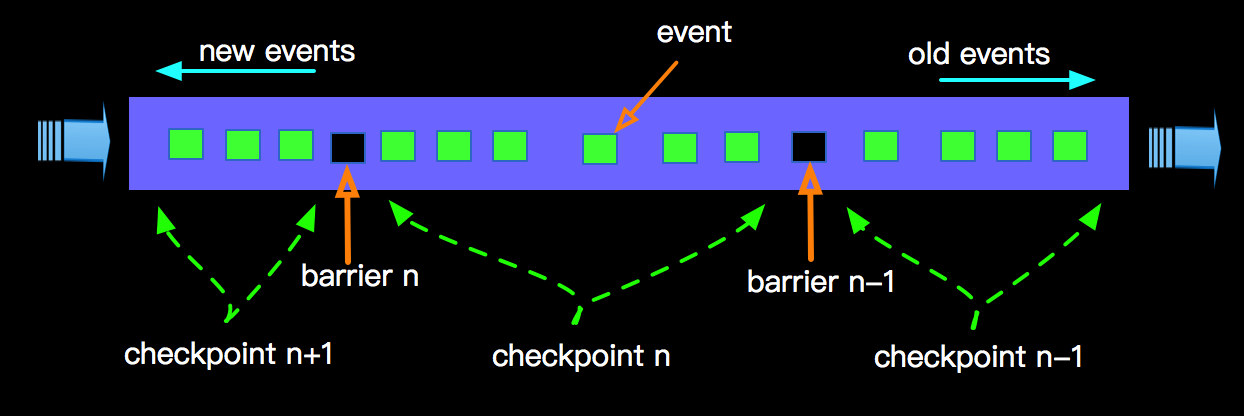 生成的snapshot会存储到StateBackend中,相关State的介绍可以查阅 Flink State 。这样在进行failover时候,从最后一次成功的checkpoint进行恢复;
生成的snapshot会存储到StateBackend中,相关State的介绍可以查阅 Flink State 。这样在进行failover时候,从最后一次成功的checkpoint进行恢复;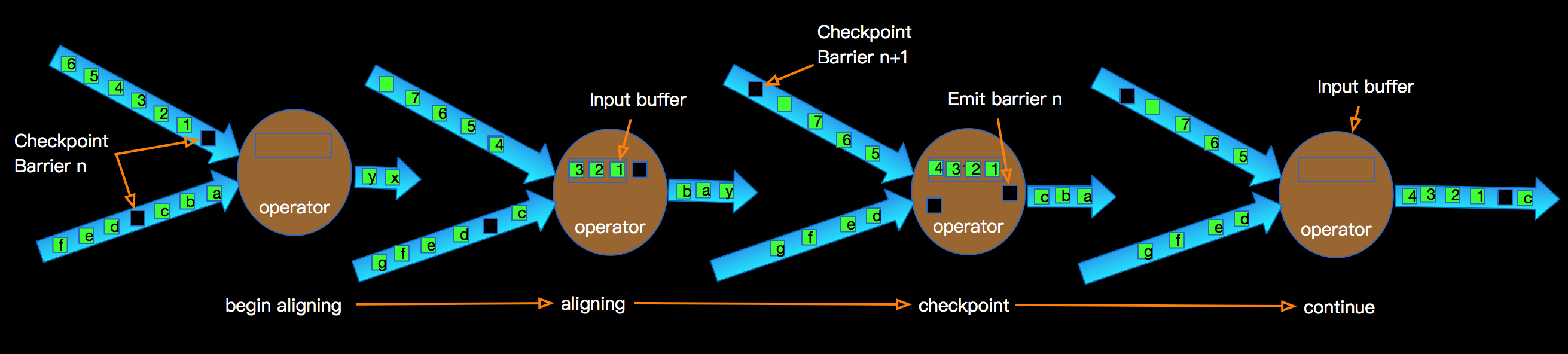 上图示意了某个节点进行Checkpointing的过程:
上图示意了某个节点进行Checkpointing的过程: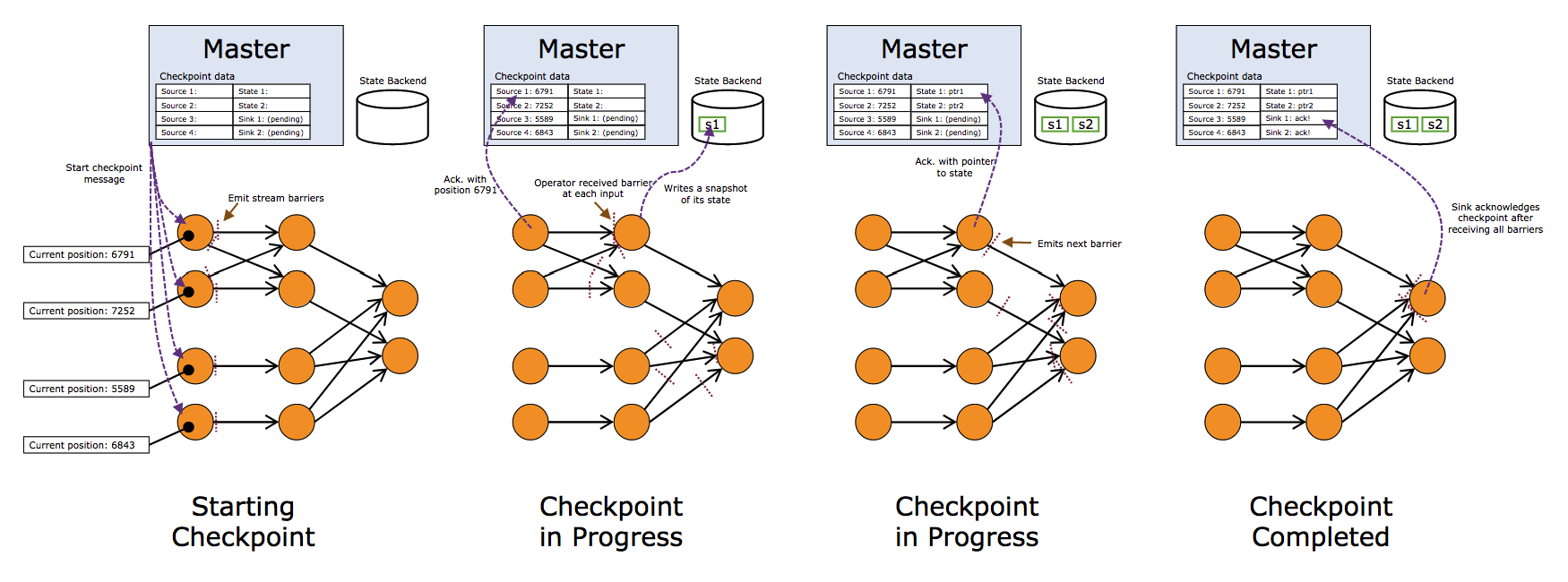 上图我们看到一个完整的Blink任务进行Checkpointing的过程,JM触发Soruce发射barriers,当某个Operator接收到上游发下来的barrier,开始进行barrier的处理,整体根据DAG自上而下的逐个节点进行Checkpointing,并持久化到Statebackend。一直到DAG的sink节点。
上图我们看到一个完整的Blink任务进行Checkpointing的过程,JM触发Soruce发射barriers,当某个Operator接收到上游发下来的barrier,开始进行barrier的处理,整体根据DAG自上而下的逐个节点进行Checkpointing,并持久化到Statebackend。一直到DAG的sink节点。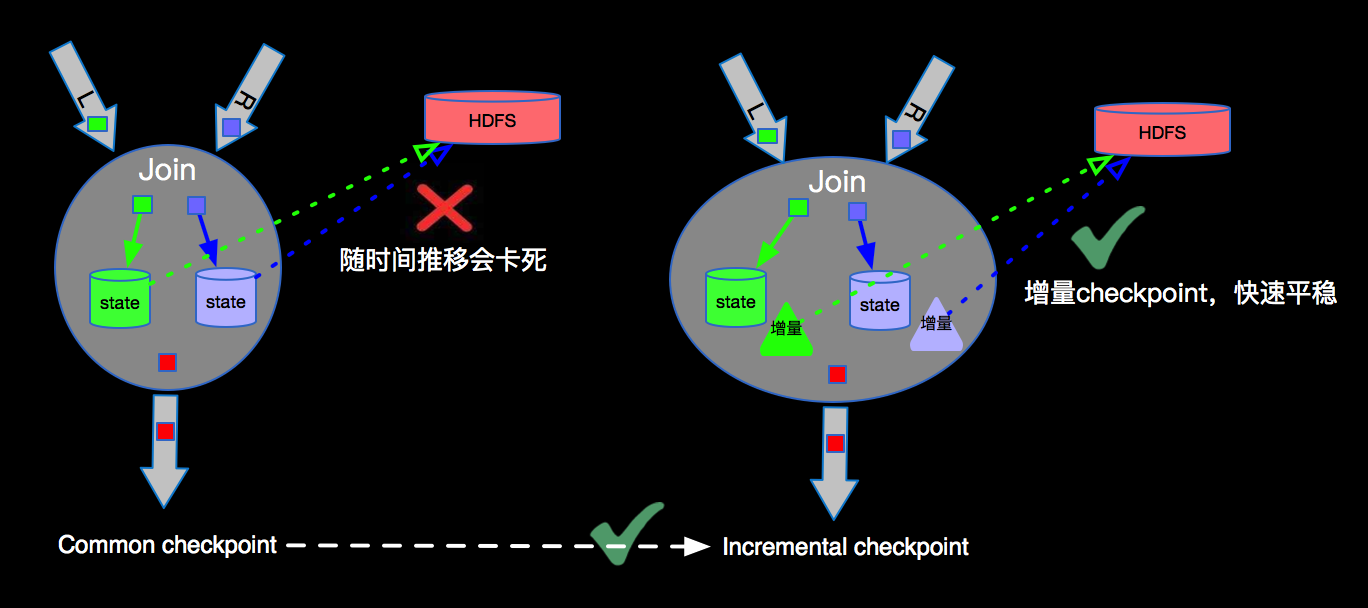 由于流上数据源源不断,随着时间的增加,每次checkpoint产生的snapshot的文件(RocksDB的sst文件)会变的非常庞大,增加网络IO,拉长checkpoint时间,最终导无法完成checkpoint,Flink失去failover的能力。为了解决checkpoint不断变大的问题,Flink内部实现了Incremental checkpoint,这种增量进行checkpoint的机制,会大大减少checkpoint时间,并且如果业务数据稳定的情况下每次checkpoint的时间是相对稳定的,根据不同的业务需求设定checkpoint的interval,稳定快速的进行checkpointing,保障Blink任务在遇到故障时候可以顺利的进行failover。Incremental checkpoint的优化对于Flink成百上千的任务节点带来的利好不言而喻。
由于流上数据源源不断,随着时间的增加,每次checkpoint产生的snapshot的文件(RocksDB的sst文件)会变的非常庞大,增加网络IO,拉长checkpoint时间,最终导无法完成checkpoint,Flink失去failover的能力。为了解决checkpoint不断变大的问题,Flink内部实现了Incremental checkpoint,这种增量进行checkpoint的机制,会大大减少checkpoint时间,并且如果业务数据稳定的情况下每次checkpoint的时间是相对稳定的,根据不同的业务需求设定checkpoint的interval,稳定快速的进行checkpointing,保障Blink任务在遇到故障时候可以顺利的进行failover。Incremental checkpoint的优化对于Flink成百上千的任务节点带来的利好不言而喻。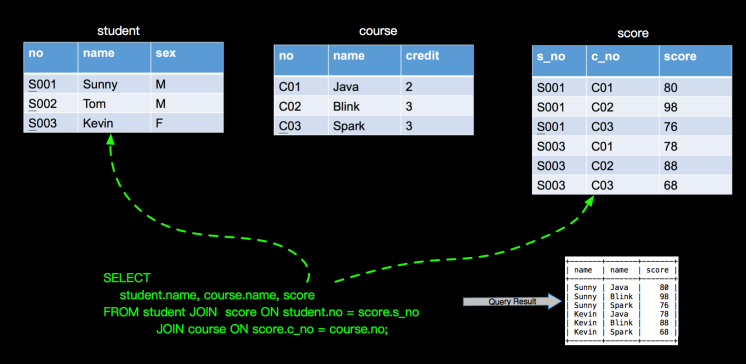
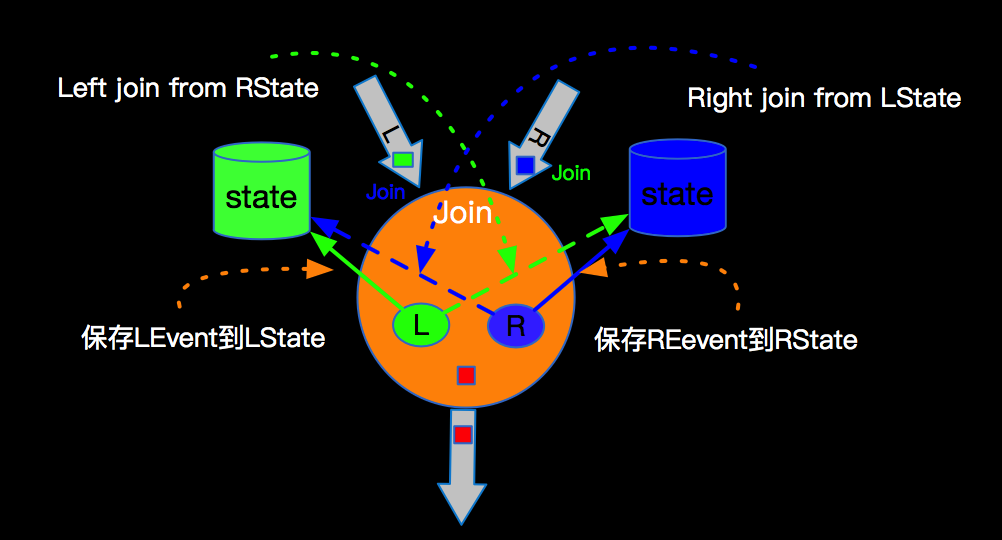
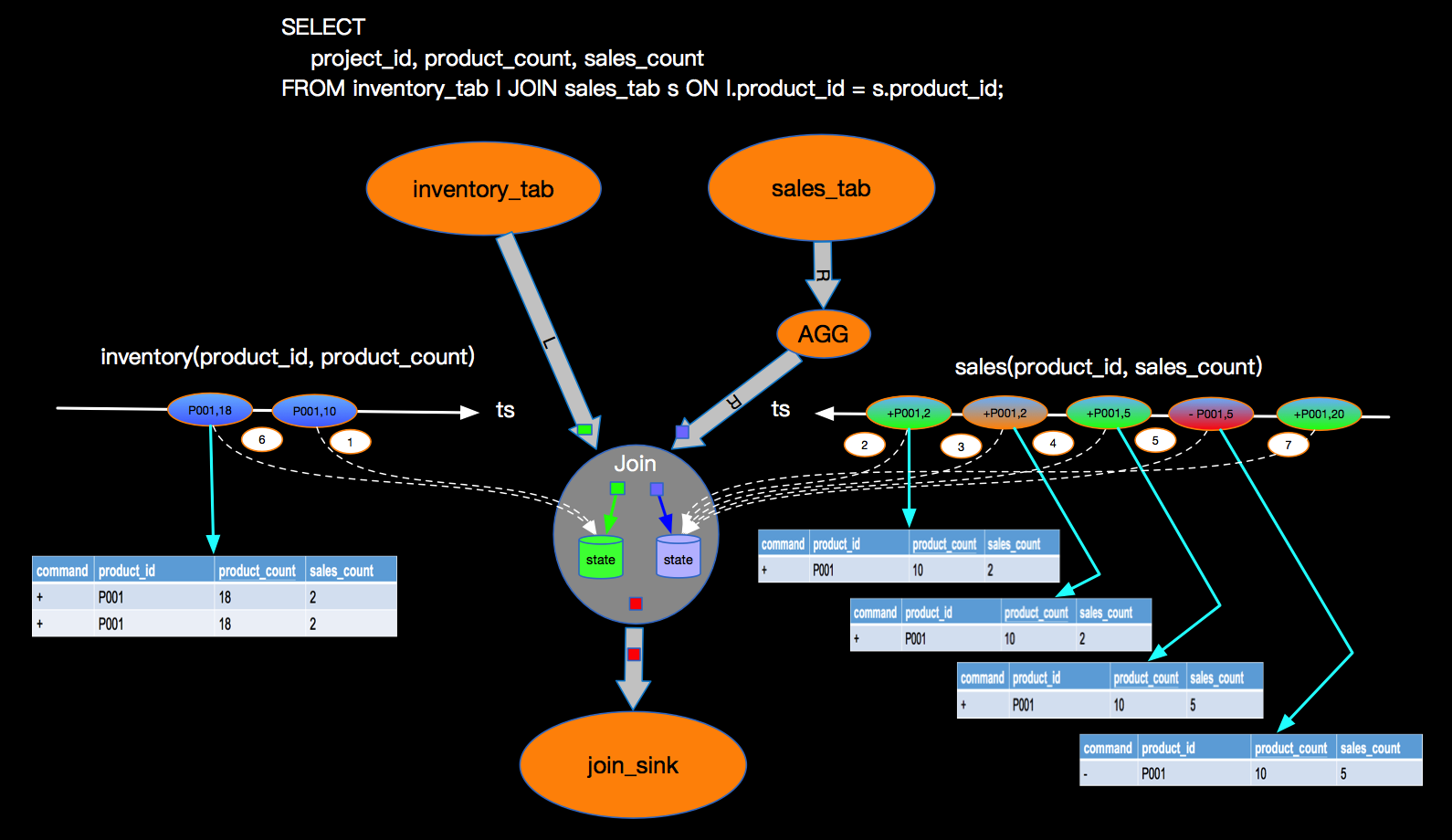
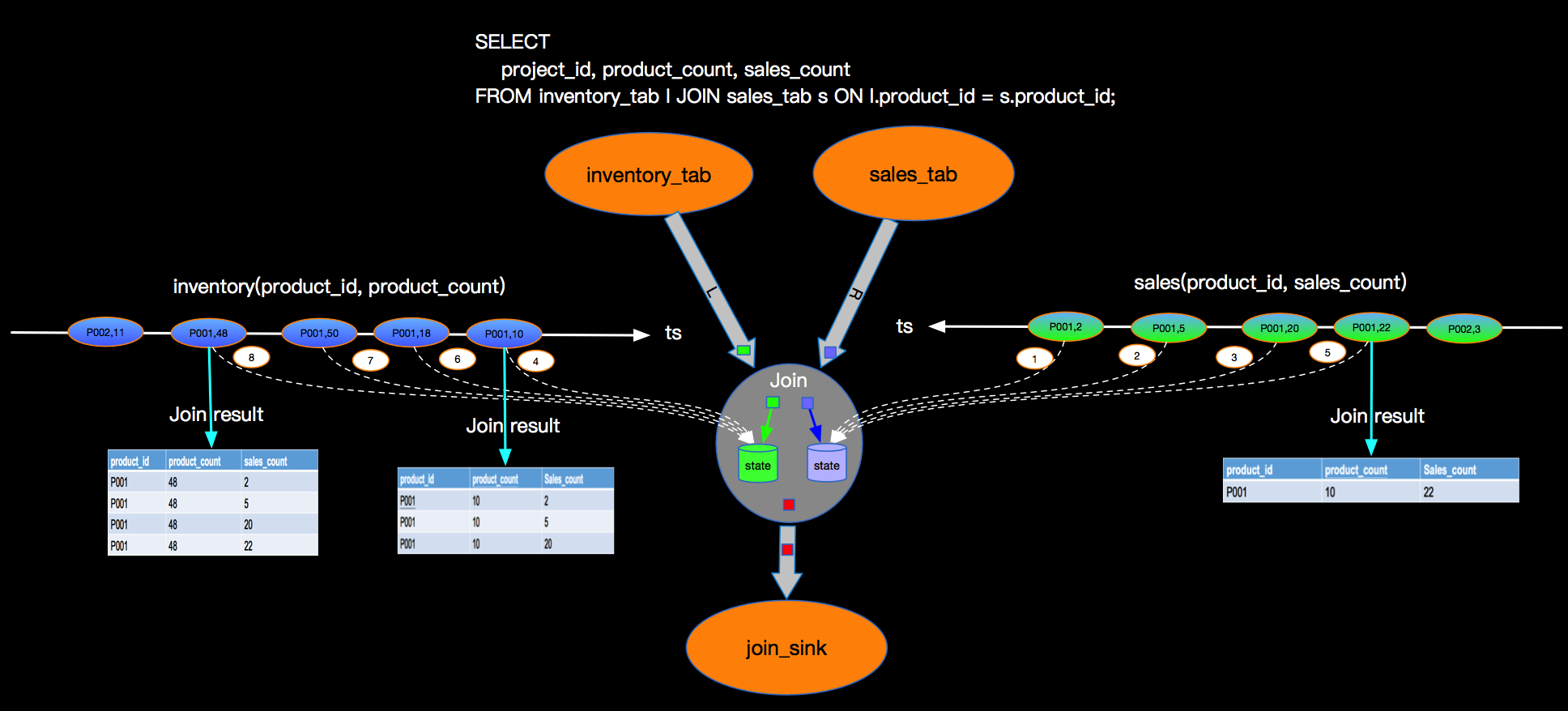 双流JOIN两边事件都会存储到State里面,如上,事件流按照标号先后流入到join节点,我们假设右边流比较快,先流入了3个事件,3个事件会存储到state中,但因为左边还没有数据,所有右边前3个事件流入时候,没有join结果流出,当左边第一个事件序号为4的流入时候,先存储左边state,再与右边已经流入的3个事件进行join,join的结果如图 三行结果会流入到下游节点sink。当第5号事件流入时候,也会和左边第4号事件进行join,流出一条jion结果到下游节点。这里关于INNER JOIN的语义和大家强调两点:
双流JOIN两边事件都会存储到State里面,如上,事件流按照标号先后流入到join节点,我们假设右边流比较快,先流入了3个事件,3个事件会存储到state中,但因为左边还没有数据,所有右边前3个事件流入时候,没有join结果流出,当左边第一个事件序号为4的流入时候,先存储左边state,再与右边已经流入的3个事件进行join,join的结果如图 三行结果会流入到下游节点sink。当第5号事件流入时候,也会和左边第4号事件进行join,流出一条jion结果到下游节点。这里关于INNER JOIN的语义和大家强调两点: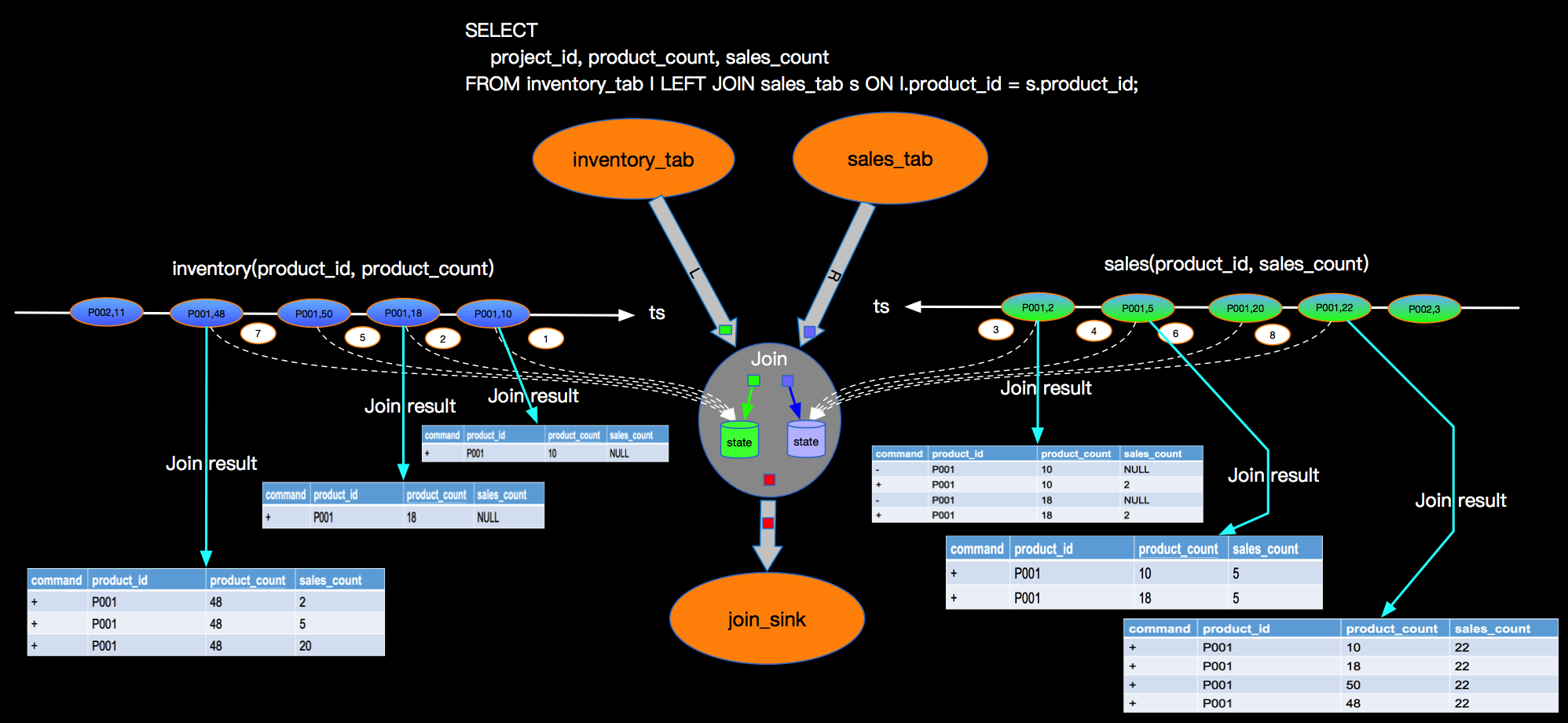 下图也是表达LEFT JOIN的语义,只是展现方式不同:
下图也是表达LEFT JOIN的语义,只是展现方式不同:
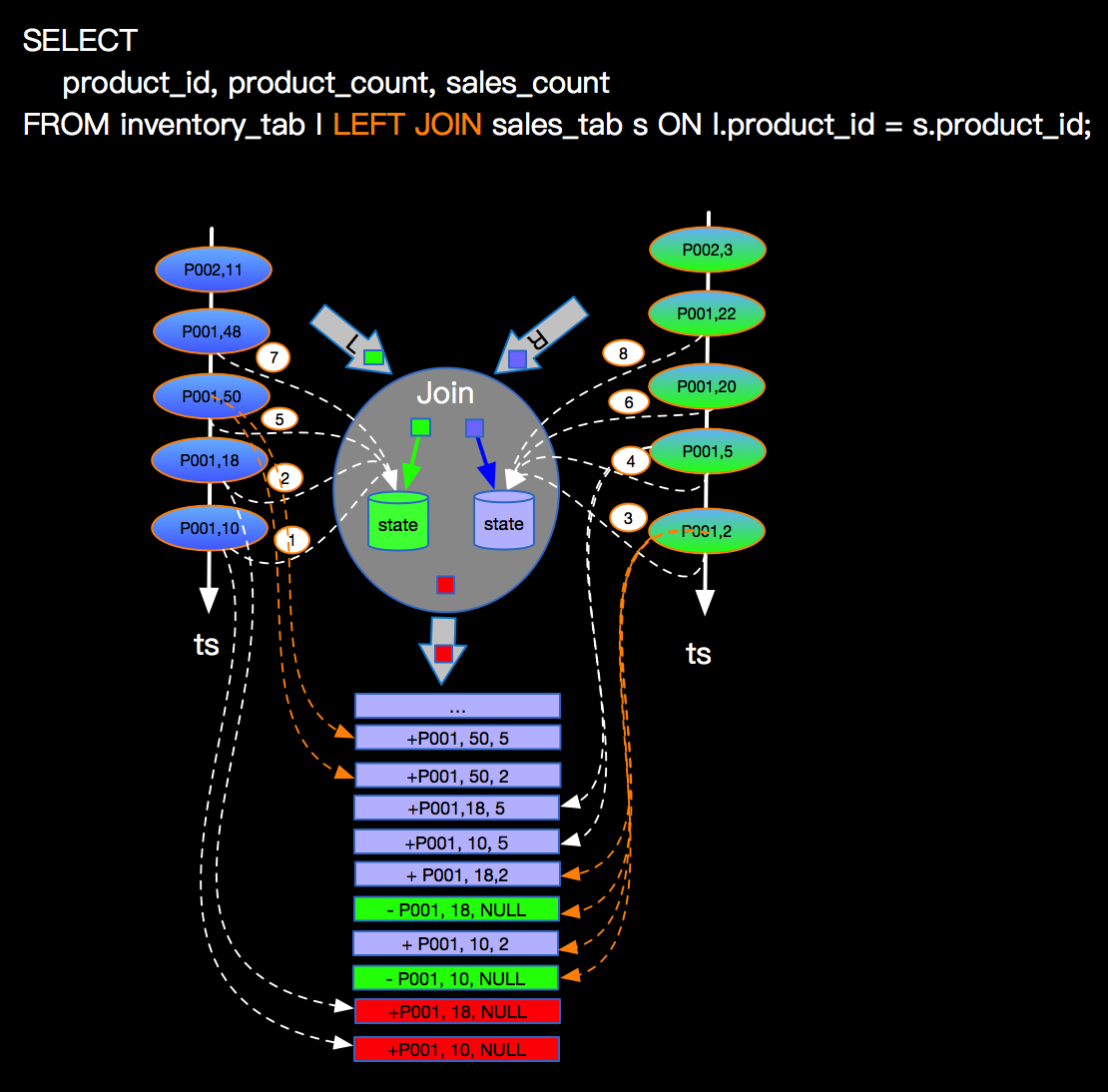 上图主要关注点是当左边先流入1,2事件时候,右边没有可以join的事件时候会向下游发送左边事件并补NULL向下游发出,当右边第一个相同的Join key到来的时候会将左边先来的事件发出的带有NULL的事件撤回(对应上面command的-记录,+代表正向记录,-代表撤回记录)。这里强调三点:
上图主要关注点是当左边先流入1,2事件时候,右边没有可以join的事件时候会向下游发送左边事件并补NULL向下游发出,当右边第一个相同的Join key到来的时候会将左边先来的事件发出的带有NULL的事件撤回(对应上面command的-记录,+代表正向记录,-代表撤回记录)。这里强调三点: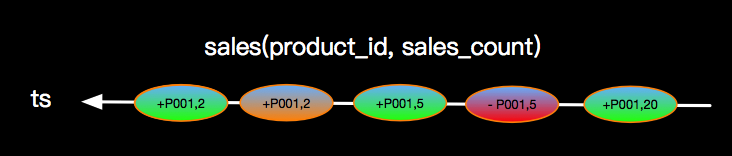 上图示例是连续产生了2笔销售数量一样的订单,同时在产生一笔销售数量为5的订单之后,有将该订单取消了(或者退货了),这样在事件流上面就会是上图的示意,这种情况Blink内部如何支撑呢?
根据JOIN的语义以INNER JOIN为例,右边有两条相同的订单流入,我们就应该想下游输出两条JOIN结果,当有撤回的事件流入时候,我们也需要将已经下发下游的JOIN事件撤回,如下:
上图示例是连续产生了2笔销售数量一样的订单,同时在产生一笔销售数量为5的订单之后,有将该订单取消了(或者退货了),这样在事件流上面就会是上图的示意,这种情况Blink内部如何支撑呢?
根据JOIN的语义以INNER JOIN为例,右边有两条相同的订单流入,我们就应该想下游输出两条JOIN结果,当有撤回的事件流入时候,我们也需要将已经下发下游的JOIN事件撤回,如下:
 上面的场景以及LEFT JOIN部分介绍的撤回情况,需要Blink内部需要处理几个核心点:
上面的场景以及LEFT JOIN部分介绍的撤回情况,需要Blink内部需要处理几个核心点: 假设在实际业务中有这这样的特点,大部分时候当A事件流入的时候,B还没有可以JION的数据,但是B来的时候,A已经有可以JOIN的数据了,这特点就会导致,A LEFT JOIN B 会产生大量的 (A, NULL),其中包括B里面的 cCol 列也是NULL,这时候当与C进行LEFT JOIN的时候,首先Blink内部会利用cCol对AB的JOIN产生的事件流进行Shuffle, cCol是NULL进而是下游节点大量的NULL事件流入,造成热点。那么这问题如何解决呢?
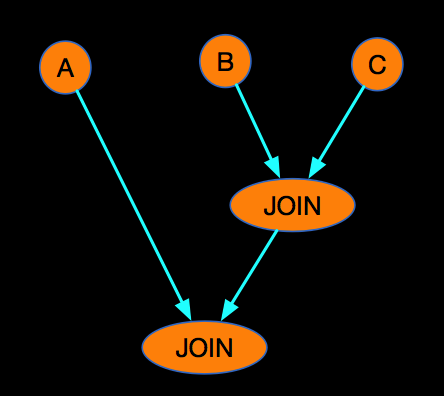
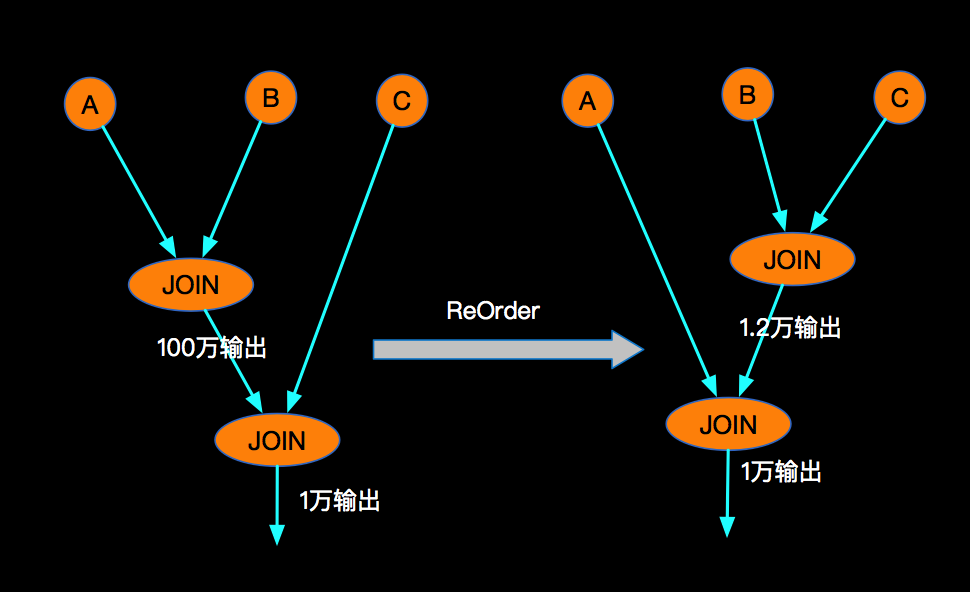
我们可以改变JOIN的先后顺序,来保证A LEFT JOIN B 不会产生NULL的热点问题,如下:
假设在实际业务中有这这样的特点,大部分时候当A事件流入的时候,B还没有可以JION的数据,但是B来的时候,A已经有可以JOIN的数据了,这特点就会导致,A LEFT JOIN B 会产生大量的 (A, NULL),其中包括B里面的 cCol 列也是NULL,这时候当与C进行LEFT JOIN的时候,首先Blink内部会利用cCol对AB的JOIN产生的事件流进行Shuffle, cCol是NULL进而是下游节点大量的NULL事件流入,造成热点。那么这问题如何解决呢?
我们可以改变JOIN的先后顺序,来保证A LEFT JOIN B 不会产生NULL的热点问题,如下:
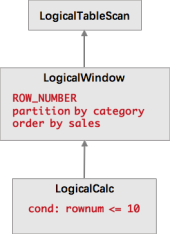 LogicalWindow 会对所有数据进行排名,也就是说每当到达一个数据,就要对历史数据进行重排序,并输出历史数据的新的排名,然后 LogicalCalc 节点会根据排名进行过滤。这在性能上是非常糟糕的,因为这无限放大了流量。而我们知道,最优的流式 TopN 的计算只需要维护一个 N 元素大小的小根堆,每当有数据到达时,只需要与堆顶元素比较,如果比堆顶元素还小,则直接丢弃;如果比堆顶元素大,则更新小根堆,并输出更新后的排行榜。也就是说我们不需要分为两个节点进行计算,不需要将所有数据进行排序,只需要在一个节点中就可以高效地完成计算。所以我们在查询优化器中加入了一条规则,在使用 TopN 语法时,将 LogicalWindow 和 LogicalCalc 合并成了 LogicalRank 节点。LogicalRank 在翻译成物理执行计划时,会使用一个经过特殊设计的 TopN 算子。
LogicalWindow 会对所有数据进行排名,也就是说每当到达一个数据,就要对历史数据进行重排序,并输出历史数据的新的排名,然后 LogicalCalc 节点会根据排名进行过滤。这在性能上是非常糟糕的,因为这无限放大了流量。而我们知道,最优的流式 TopN 的计算只需要维护一个 N 元素大小的小根堆,每当有数据到达时,只需要与堆顶元素比较,如果比堆顶元素还小,则直接丢弃;如果比堆顶元素大,则更新小根堆,并输出更新后的排行榜。也就是说我们不需要分为两个节点进行计算,不需要将所有数据进行排序,只需要在一个节点中就可以高效地完成计算。所以我们在查询优化器中加入了一条规则,在使用 TopN 语法时,将 LogicalWindow 和 LogicalCalc 合并成了 LogicalRank 节点。LogicalRank 在翻译成物理执行计划时,会使用一个经过特殊设计的 TopN 算子。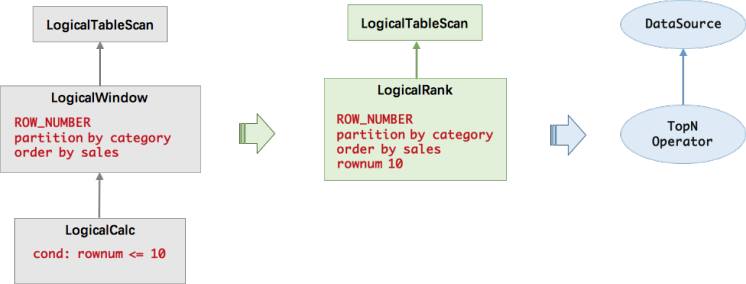 TopN 算子的实现上主要有两个数据结构,一个是 TreeMap,另一个是 MapState。TreeMap 的作用类似于上文的小根堆,有序地存放了排名前 N 的元素。但是 TreeMap 是个内存数据结构,在 failover 后会丢失,无法保证数据的一致性。因此我们还有一个 MapState 结构,MapState 是 Flink 提供的状态接口,用来存储 TopN 的数据(保证数据不丢)。当有 failover 发生后,MapState 能保证状态的恢复,而 TreeMap 会从 MapState 中重新构造出来。我们并有没有把顺序也存到状态中去,因为顺序是可以在恢复时重构的。因为每一次状态的读写操作都会涉及到序列化/反序列化,往往是性能的瓶颈,所以 TreeMap 的主要作用是降低了对 MapState 状态的读写操作。对大部分数据来说都是与 TreeMap 进行交互,不需要对 MapState 进行读写的,全是内存操作,所以 TopN 的性能是非常高的。
TopN 算子的实现上主要有两个数据结构,一个是 TreeMap,另一个是 MapState。TreeMap 的作用类似于上文的小根堆,有序地存放了排名前 N 的元素。但是 TreeMap 是个内存数据结构,在 failover 后会丢失,无法保证数据的一致性。因此我们还有一个 MapState 结构,MapState 是 Flink 提供的状态接口,用来存储 TopN 的数据(保证数据不丢)。当有 failover 发生后,MapState 能保证状态的恢复,而 TreeMap 会从 MapState 中重新构造出来。我们并有没有把顺序也存到状态中去,因为顺序是可以在恢复时重构的。因为每一次状态的读写操作都会涉及到序列化/反序列化,往往是性能的瓶颈,所以 TreeMap 的主要作用是降低了对 MapState 状态的读写操作。对大部分数据来说都是与 TreeMap 进行交互,不需要对 MapState 进行读写的,全是内存操作,所以 TopN 的性能是非常高的。
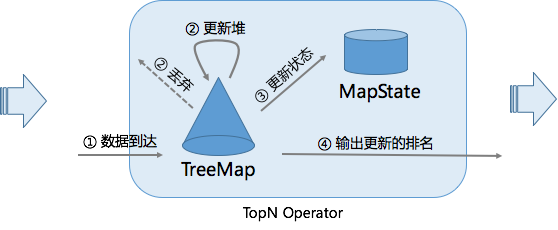 TopN 算子的主要处理流程是,每当有数据到达时,会与 TreeMap 的最小的元素比较,如果比它小,那么该数据就不可能是 TopN 的一员,直接丢弃即可。如果比它大,那么就会先更新 TreeMap,同时更新 MapState 中的存的数据。最后输出更新后的排行榜。为了减少冗余数据的输出,我们只会输出排名发生变化的数据。例如原先的第7名上升到了第六名,那么只需要输出新的第六名和第七名即可。
TopN 算子的主要处理流程是,每当有数据到达时,会与 TreeMap 的最小的元素比较,如果比它小,那么该数据就不可能是 TopN 的一员,直接丢弃即可。如果比它大,那么就会先更新 TreeMap,同时更新 MapState 中的存的数据。最后输出更新后的排行榜。为了减少冗余数据的输出,我们只会输出排名发生变化的数据。例如原先的第7名上升到了第六名,那么只需要输出新的第六名和第七名即可。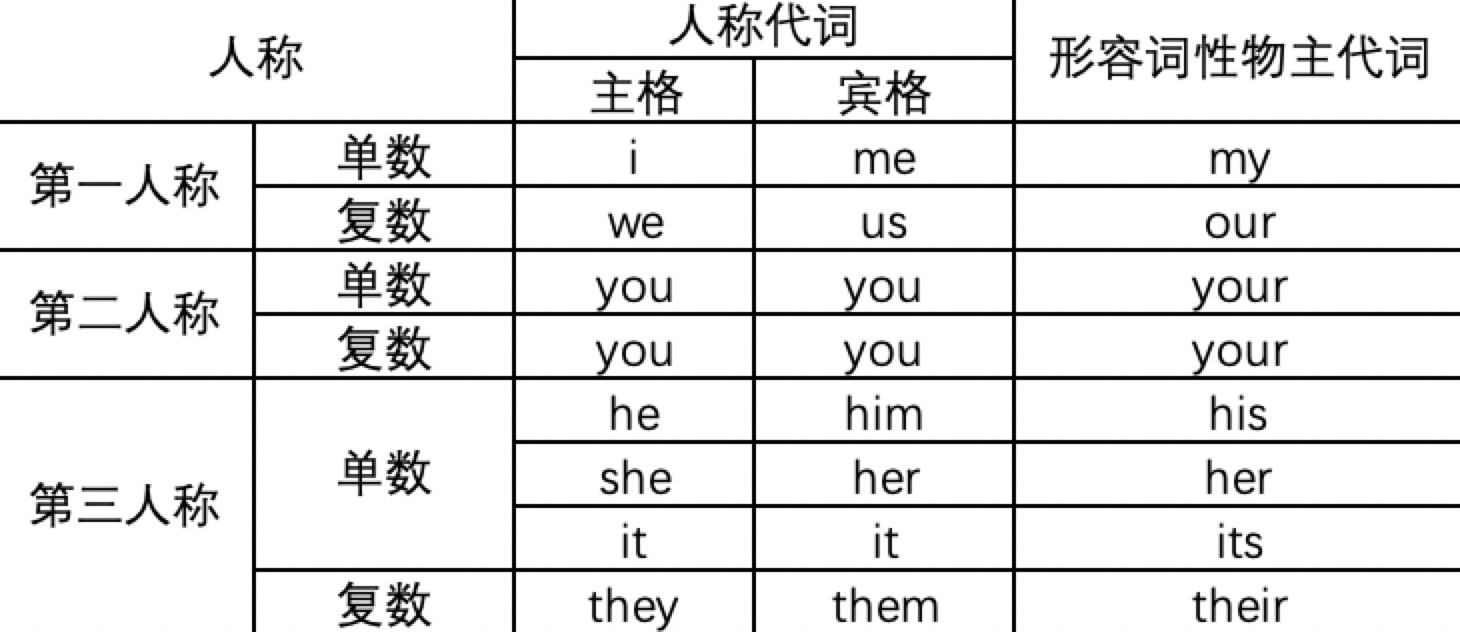
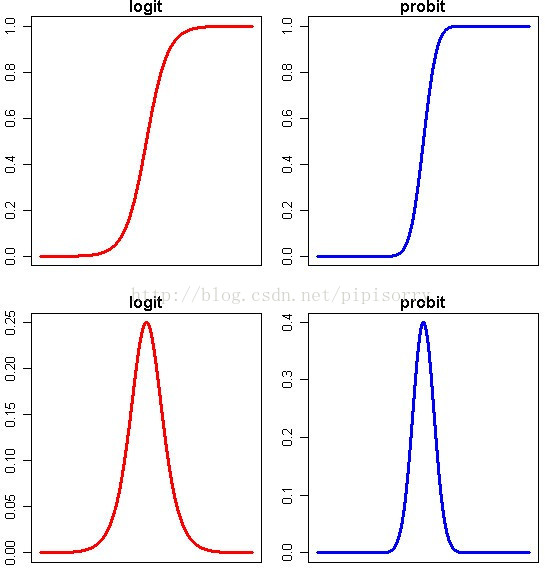
 Note: 上半部分图形显示了概率P随着自变量变化而变化的情况,下半部分图形显示了这种变化的速度的变化。可以看得出来,概率P与自变量仍然存在或多或少的线性关系,主要是在头尾两端被连接函数扭曲了,从而实现了[0,1]限制。同时,自变量取值靠近中间的时候,概率P变化比较快,自变量取值靠近两端的时候,概率P基本不再变化。这就跟我们的直观理解相符合了,似乎是某种边际效用递减的特点。
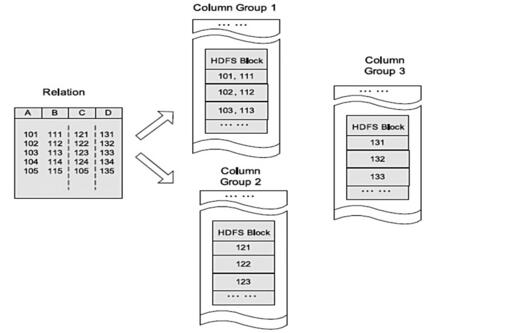
Note: 上半部分图形显示了概率P随着自变量变化而变化的情况,下半部分图形显示了这种变化的速度的变化。可以看得出来,概率P与自变量仍然存在或多或少的线性关系,主要是在头尾两端被连接函数扭曲了,从而实现了[0,1]限制。同时,自变量取值靠近中间的时候,概率P变化比较快,自变量取值靠近两端的时候,概率P基本不再变化。这就跟我们的直观理解相符合了,似乎是某种边际效用递减的特点。 有了机架感知,NameNode就可以画出上图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离。
有了机架感知,NameNode就可以画出上图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离。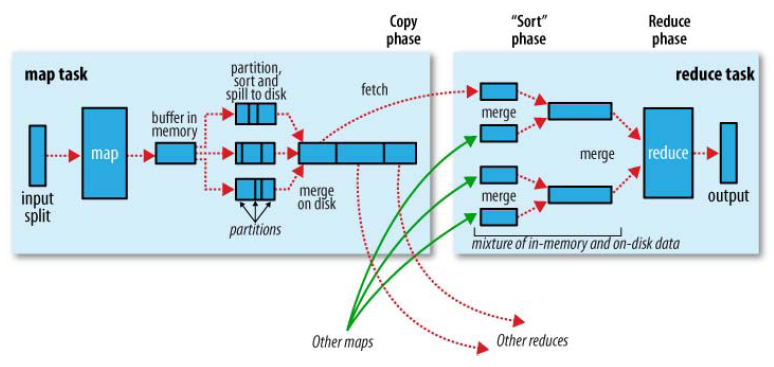
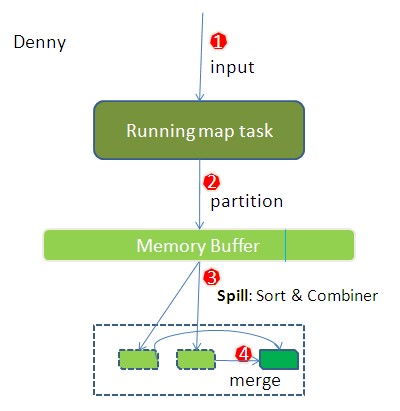
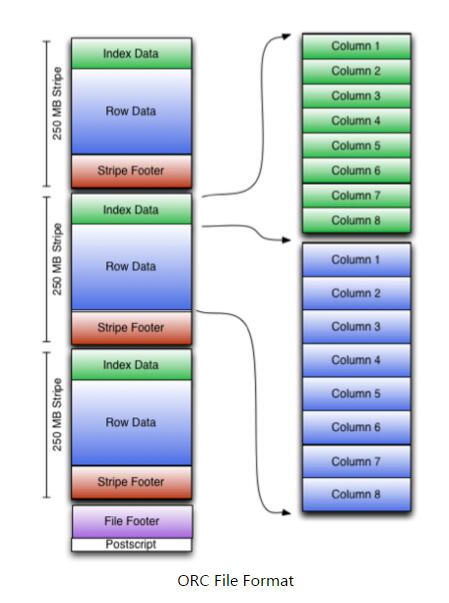
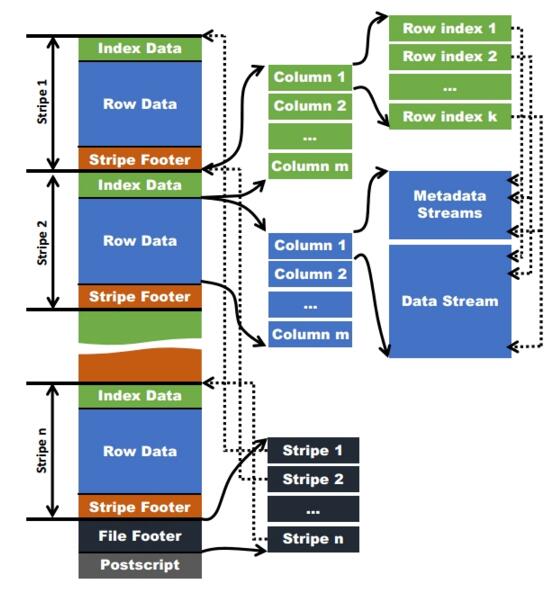
 环形缓冲其实就是一个字节数组.存储着map的输出结果,当缓冲区快满的时候(80%)需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据.
环形缓冲其实就是一个字节数组.存储着map的输出结果,当缓冲区快满的时候(80%)需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据.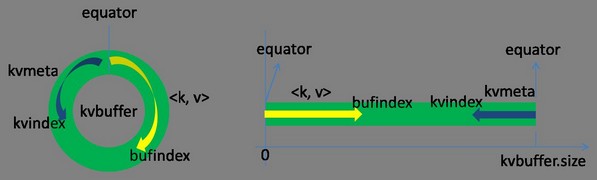 bufferindex一直往上增长,例如最初为0,写入一个int类型的key之后变为4,写入一个int类型的value之后变成8.kvmeta的存放指针kvindex每次都是向下跳四个”格子”.索引是对key-value在kvbuffer中的索引,是个四元组,占用四个Int长度,包括:value的起始位置,key的起始位置,partition值,value的长度.
bufferindex一直往上增长,例如最初为0,写入一个int类型的key之后变为4,写入一个int类型的value之后变成8.kvmeta的存放指针kvindex每次都是向下跳四个”格子”.索引是对key-value在kvbuffer中的索引,是个四元组,占用四个Int长度,包括:value的起始位置,key的起始位置,partition值,value的长度.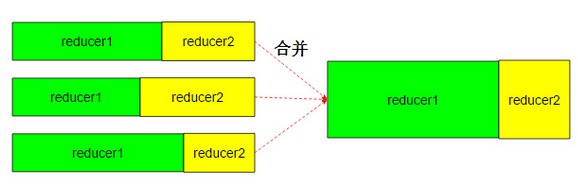
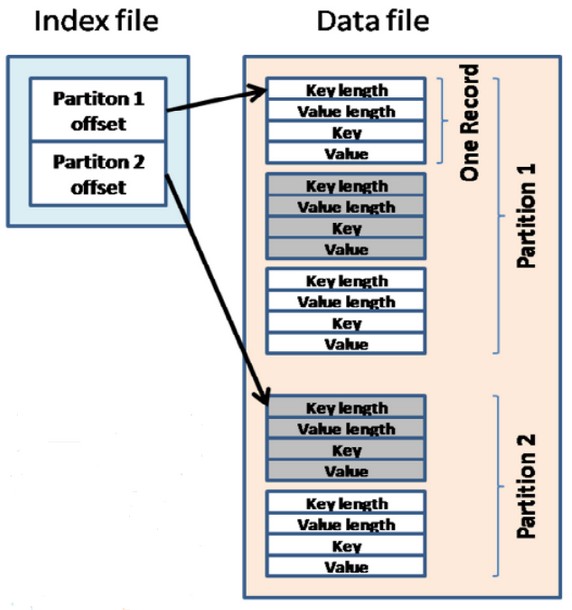
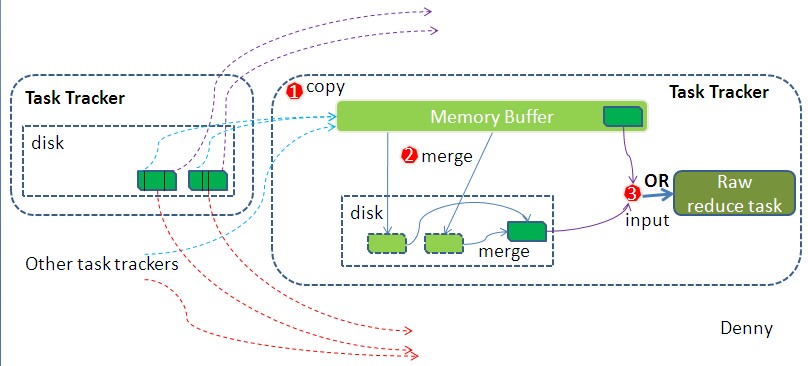 reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件.
reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件.